반응형
numpy 특징
- Numerical Python
- 강력한 다차원 배열과 행렬 연산
- 다양한 선형 대수학 함수와 난수
- 간결한 코딩
for문과 numpy 비교
# 두 개의 리스트에 난수(random number)를 저장
import numpy as np
n = 100000
w = [np.random.random() for _ in range(n)]
x = [np.random.random() for _ in range(n)]
# list의 값을 np 배열로 복사
wnum = np.array(w) # ndarray type
xnum = np.array(x)
%%time
total = 0
for i in range(n):
total += w[i]*x[i]
print(total)
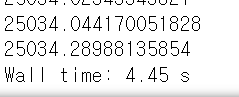
%%time
total = np.dot(wnum, xnum)
print(total)
코드가 훨씬 간결해졌을 뿐만 아니라, 속도가 엄청 빠르다.
numpy 배열의 속성
ndarray(넘파이 클래스) 속성
- ndim : 차원, axis 개수, rank
- shape : 형상, 각 차원의 배열의 크기
- size : 배열의 모든 원소의 개수
- dtype : 원소의 자료 형식

코딩을 할 때 이러한 변수의 속성과 타입을 알고 있으면, 디버깅을 할 때 매우 수월하게 작업할 수 있다.
아래와 같은 funtion을 만들어 사용할 수도 있다.
# 배열의 속성 출력 함수
def pprint(arr):
print("type:{}, size:{}".format(type(arr),arr.size))
print("shape:{},ndim/rank:{},dtype{}".
format(arr.shape, arr.ndim, arr.dtype))
print("Array's Data:")
print(arr)배열의 생성
- np.array() - 리스트, 튜플 이용
- 배열 생성 함수
리스트 튜플 사용
a = np.array([1,2,3,4]) # list
a = np.array((1,2,3,4)) # tuple
a = np.array(1,2,3,4) # wrong
배열 생성 함수 사용
a = np.arange(12)
pprint(a) # 배열의 속성 함수 사용 예시
a = np.arange(12, dtype=float).reshape(3, 4)
pprint(a)
이렇게 shape와 dtype도 바꿀 수 있다.
아래와 같은 함수도 있다.

full : 사용자가 지정한 하나의 값으로 배열을 생성

empty : 임의의 값으로

eye : 단위 행렬 생성
데이터 생성 함수
np.arange
# start부터 Stop미만까지 step간격으로 데이터를 생성
# arrange([start,] stop[,step,], dtype=None)
np.arange(0, 100, 3, dtype=float)
import matplotlib.pyplot as plt
%matplotlib inline
a = np.arange(0, 100, 6, dtype=float)
plt.plot(a, 'or')
plt.show()
np.linspace
# num 개수 만큼 균일한 간격으로 추출
# endpoint : end값을 포함할 지 여부 (default는 True)
# retstep : 배열의 간격 출력 (default= False)
np.linspace(0, 100, num=20, endpoint=True, retstep=True)
>>> (array([ 0. , 5.26315789, 10.52631579, 15.78947368,
21.05263158, 26.31578947, 31.57894737, 36.84210526,
42.10526316, 47.36842105, 52.63157895, 57.89473684,
63.15789474, 68.42105263, 73.68421053, 78.94736842,
84.21052632, 89.47368421, 94.73684211, 100. ]),
5.2631578947368425)import matplotlib.pyplot as plt
%matplotlib inline
x = np.linspace(0, 2*np.pi)
y = np.sin(x)
plt.plot(x, y)
plt.show()
logspace
# logspace는 start부터 stop의 범위에서 로그 스케일로 num 개의 데이터를 생성
# 이 경우, 30개의 점과 출력범위 3^1(3) ~ 3^5(243)
a = np.logspace(1, 5, num=30, endpoint=True, base = 3.0, dtype=float)
plt.plot(a, 'xb')
plt.show()
numpy 인덱싱 및 슬라이싱


슬라이싱을 통해 생성된 서브배열

슬라이싱과 인덱싱은 원래 원본 데이터를 가리키고 있을 뿐, 원본 데이터 그 자체이므로, 서브배열을 변경하는 것으로 원본 배열이 변경된다.
배열을 복사하려면?
배열사본변수 = 원본배열.copy() 메소드 함수를 사용
불린 배열 인덱싱

반응형
'Programming > Python' 카테고리의 다른 글
| numpy.random 모듈 난수 배열의 생성 (0) | 2022.01.14 |
|---|---|
| numpy 브로드캐스팅 (0) | 2022.01.14 |
| 함수와 뉴런, 인공신경망의 구현 (0) | 2022.01.14 |
| 파이썬 Numpy 다차원 배열 (0) | 2022.01.06 |
| 파이썬 NumPy 데이터타입 (0) | 2022.01.06 |



