반응형
머신러닝을 분류하는 또 다른 기준 : 어떻게 일반화하는가?
대부분의 머신러닝 목적은 예측을 하는 것.
사례기반 학습
- 주어진 예제를 통해 학습
- measure of similarity(유사도)를 가지고 사례를 일반화
- 일반화시킨 예제를 가지고 비교해 새로운 것을 예측
모델 기반 학습
- 다양한 예제들을 통해 모델을 만듬

- 예시 모델 : linear model
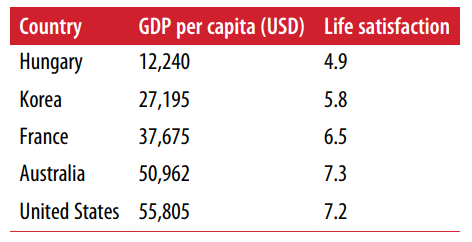
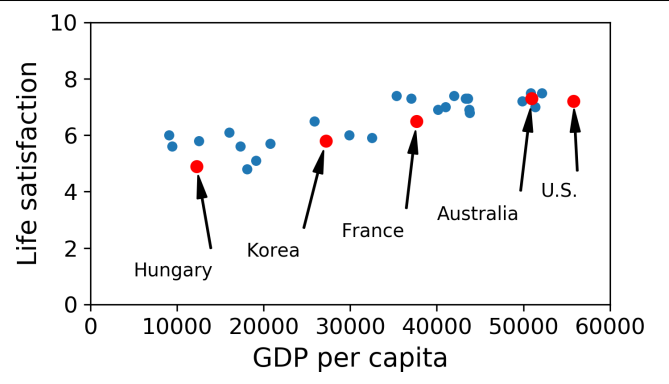
$Life\;satisfation = \theta_0+\theta_1 \times GDP\;per\;capita$
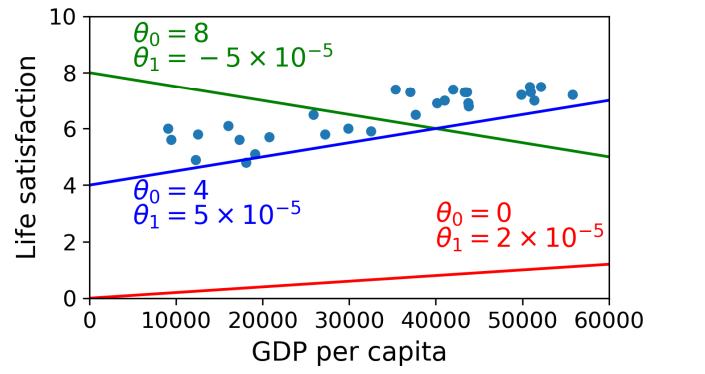
- 모델을 사용하기 전에 먼저 $\theta_0$와 $\theta_1$의 값을 지정해야 함
어떤 값이 이 모델을 제일 효과적으로 퍼폼하게 할까?
$\to$ specify performance measure- utility function(how good it is) or cost function(how bad it is)
- 회귀문제에서는 보통 cost function을 사용
모델의 예측과 트레이닝 데이터 간의 거리를 좁히는 것이 목적- 선형회귀알고리즘이 여기서 사용됨
알고리즘에 예제를 주어서 최적의 파라미터를 찾도록 하는
$\to$ 모델을 훈련시킨다고 표현
- 선형회귀알고리즘이 여기서 사용됨

- 이렇게 모델을 찾고나면 OECD 데이터에서는 찾을 수 없는 나라에 대한 삶의 만족도도 예측해볼 수 있음
- 사이프러스의 경우
$Life\;satisfation = 4.85+ 22,587 \times 4.91 \times 10^{-5} = 5.96$
반응형
'Mathematics > Machine Learning' 카테고리의 다른 글
| Testing and validating machine learning (0) | 2022.01.17 |
|---|---|
| 머신러닝 결과를 나쁘게 하는 것 (0) | 2022.01.17 |
| 배치 학습과 온라인 학습 (0) | 2022.01.17 |
| 머신러닝의 종류(2) - 비지도학습 (0) | 2022.01.16 |
| 머신러닝의 종류(1) - 지도학습 (0) | 2022.01.16 |


